Consider five taxa (A, B, C, D, E)
with the following distance matrix (the data could be molecular or morphological distances):
| A | B | C | D | E | |
| A | 0 | - | - | - | - |
| B | 20 | 0 | - | - | - |
| C | 60 | 50 | 0 | - | - |
| D | 100 | 90 | 40 | 0 | - |
| E | 90 | 80 | 50 | 30 | 0 |
A & B are closest (20
units): join them into one cluster (AB) joining at 20, and recalculate
the average distance from
C, D, and E to (AB).
[For example, the distance from C to (AB) = (60 + 50)/2 =
55, and the distance from D
to (AB) = (100 + 90)/2 = 95].
This gives:
| (AB) | C | D | E | |
| (AB) | 0 | - | - | - |
| C | 55 | 0 | - | - |
| D | 95 | 40 | 0 | - |
| E | 85 | 50 | 30 | 0 |
D & E are closest (30
units): join them into one cluster (DE) joining at 30, and recalculate
the average distances between (AB), C, and (DE). [For
example, the distance from (AB) to (DE) = (95 + 85)/2 = 90].
This gives:
| (AB) | C | (DE) | |
| (AB) | 0 | - | - |
| C | 55 | 0 | - |
| (DE) | 90 | 45 | 0 |
C & (DE) are closest
(45 units): join them into one cluster (CDE) joining at 45, and
recalculate the average distance between (CDE) and (AB).
This gives:
| (AB) | (CDE) | |
| (AB) | 0 | - |
| (CDE) | 72.5 | 0 |
The two clusters join at 72.5. This completes
the analysis.
The method illustrated is a Weighted PGM with Averaging (WPGMA). See the commentary on calculations for the difference between weighted and unweighted analyses (WPGMA and UPGMA).
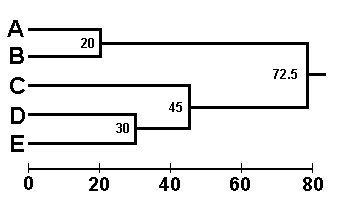
These results may be presented as a phenogram with nodes at 20, 30, 45, and 72.5 units. The phenogram can be interepreted as indicating that A & B are similar to each other, as are D & E, and that C is more similar to D & E :
Text material © 2007 by Steven M. Carr